分析Linux内核调度器源码之初始化
调度器(Scheduler)子系统是内核的核心子系统之一,负责系统内 CPU 资源的合理分配,需要能处理纷繁复杂的不同类型任务的调度需求,还需要能处理各种复杂的并发竞争环境,同时还需要兼顾整体吞吐性能和实时性要求(本身是一对矛盾体),其设计与实现都极具挑战。
为了能够理解 Linux 调度器的设计与实现,我们将以 Linux kernel 5.4 版本(TencentOS Server3 默认内核版本)为对象,从调度器子系统的初始化代码开始,分析 Linux 内核调度器的设计与实现。
二、调度器的基本概念在分析调度器的相关代码之前,需要先了解一下调度器涉及的核心数据(结构)以及它们的作用
2.1、运行队列(rq)内核会为每个 CPU 创建一个运行队列,系统中的就绪态(处于 Running 状态的)进程(task)都会被组织到内核运行队列上,然后根据相应的策略,调度运行队列上的进程到 CPU 上执行。
2.2、调度类(sched_class)内核将调度策略(sched_class)进行了高度的抽象,形成调度类(sched_class)。通过调度类可以将调度器的公共代码(机制)和具体不同调度类提供的调度策略进行充分解耦,是典型的 OO(面向对象)的思想。通过这样的设计,可以让内核调度器极具扩展性,开发者通过很少的代码(基本不需改动公共代码)就可以增加一个新的调度类,从而实现一种全新的调度器(类),比如,deadline调度类就是3.x中新增的,从代码层面看只是增加了 dl_sched_class 这个结构体的相关实现函数,就很方便的添加了一个新的实时调度类型。
目前的5.4内核,有5种调度类,优先级从高到底分布如下:
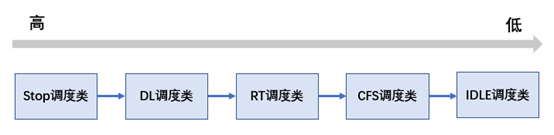
stop_sched_class:
优先级最高的调度类,它与 idle_sched_class 一样,是一个专用的调度类型(除了 migration 线程之外,其他的 task 都是不能或者说不应该被设置为 stop 调度类)。该调度类专用于实现类似 active balance 或 stop machine 等依赖于 migration 线程执行的“紧急”任务。
dl_sched_class:
deadline 调度类的优先级仅次于 stop 调度类,它是一种基于 EDL 算法实现的实时调度器(或者说调度策略)。
rt_sched_class:
rt 调度类的优先级要低于 dl 调度类,是一种基于优先级实现的实时调度器。
fair_sched_class:
CFS 调度器的优先级要低于上面的三个调度类,它是基于公平调度思想而设计的调度类型,是 Linux 内核的默认调度类。
idle_sched_class:
idle 调度类型是 swapper 线程,主要是让 swapper 线程接管 CPU,通过 cpuidle/nohz 等框架让 CPU 进入节能状态。
2.3、调度域(sched_domain)调度域是在2.6里引入内核的,通过多级调度域引入,能够让调度器更好的适应硬件的物理特性(调度域可以更好的适配 CPU 多级缓存以及 NUMA 物理特性对负载均衡所带来的挑战),实现更好的调度性能(sched_domain 是为 CFS 调度类负载均衡而开发的机制)。
2.4、调度组(sched_group)调度组是与调度域一起被引入内核的,它会与调度域一起配合,协助 CFS 调度器完成多核间的负载均衡。
2.5、根域(root_domain)根域主要是负责实时调度类(包括 dl 和 rt 调度类)负载均衡而设计的数据结构,协助 dl 和 rt 调度类完成实时任务的合理调度。在没有用 isolate 或者 cpuset cgroup 修改调度域的时候,那么默认情况下所有的CPU都会处于同一个根域。
2.6、组调度(group_sched)为了能够对系统里的资源进行更精细的控制,内核引入了 cgroup 机制来进行资源控制。而 group_sched 就是 cpu cgroup 的底层实现机制,通过 cpu cgroup 我们可以将一些进程设置为一个 cgroup,并且通过 cpu cgroup 的控制接口配置相应的带宽和 share 等参数,这样我们就可以按照 group 为单位,对 CPU 资源进行精细的控制。
三、调度器初始化(sched_init)下面进入正题,开始分析内核调度器的初始化流程,希望能通过这里的分析,让大家了解:
1、运行队列是如何被初始化的
2、组调度是如何与 rq 关联起来的(只有关联之后才能通过 group_sched 进行组调度)
3、CFS 软中断 SCHED_SOFTIRQ 注册
调度初始化(sched_init)
start_kernel
|----setup_arch
|----build_all_zonelists
|----mm_init
|----sched_init 调度初始化
调度初始化位于 start_kernel 相对靠后的位置,这个时候内存初始化已经完成,所以可以看到 sched_init 里面已经可以调用 kzmalloc 等内存申请函数了。
sched_init 需要为每个 CPU 初始化运行队列(rq)、dl/rt 的全局默认带宽、各个调度类的运行队列以及 CFS 软中断注册等工作。
接下来我们看看 sched_init 的具体实现(省略了部分代码):
void __init sched_init(void){ unsigned long ptr = 0; int i; /* * 初始化全局默认的rt和dl的CPU带宽控制数据结构 * * 这里的rt_bandwidth和dl_bandwidth是用来控制全局的DL和RT的使用带宽,防止实时进程 * CPU使用过多,从而导致普通的CFS进程出现饥饿的情况 */ init_rt_bandwidth(&def_rt_bandwidth, global_rt_period(), global_rt_runtime()); init_dl_bandwidth(&def_dl_bandwidth, global_rt_period(), global_rt_runtime()); #ifdef CONFIG_SMP /* * 初始化默认的根域 * * 根域是dl/rt等实时进程做全局均衡的重要数据结构,以rt为例 * root_domain->cpupri 是这个根域范围内每个CPU上运行的RT任务的最高优先级,以及 * 各个优先级任务在CPU上的分布情况,通过cpupri的数据,那么在rt enqueue/dequeue * 的时候,rt调度器就可以根据这个rt任务分布情况来保证高优先级的任务得到优先 * 运行 */ init_defrootdomain();#endif #ifdef CONFIG_RT_GROUP_SCHED /* * 如果内核支持rt组调度(RT_GROUP_SCHED), 那么对RT任务的带宽控制将可以用cgroup * 的粒度来控制每个group里rt任务的CPU带宽使用情况 * * RT_GROUP_SCHED可以让rt任务以cpu cgroup的形式来整体控制带宽 * 这样可以为RT带宽控制带来更大的灵活性(没有RT_GROUP_SCHED的时候,只能控制RT的全局 * 带宽使用,不能通过指定group的形式控制部分RT进程带宽) */ init_rt_bandwidth(&root_task_group.rt_bandwidth, global_rt_period(), global_rt_runtime());#endif /* CONFIG_RT_GROUP_SCHED */ /* 为每个CPU初始化它的运行队列 */ for_each_possible_cpu(i) {struct rq *rq; rq = cpu_rq(i);raw_spin_lock_init(&rq->lock);/* * 初始化rq上cfs/rt/dl的运行队列 * 每个调度类型在rq上都有各自的运行队列,每个调度类都是各自管理自己的进程 * 在pick_next_task()的时候,内核根据调度类优先级的顺序,从高到底选择任务 * 这样就保证了高优先级调度类任务会优先得到运行 * * stop和idle是特殊的调度类型,是为专门的目的而设计的调度类,并不允许用户 * 创建相应类型的进程,所以内核也没有在rq里设计对应的运行队列 */init_cfs_rq(&rq->cfs);init_rt_rq(&rq->rt);init_dl_rq(&rq->dl);#ifdef CONFIG_FAIR_GROUP_SCHED/* * CFS的组调度(group_sched),可以通过cpu cgroup来对CFS进行进行控制 * 可以通过cpu.shares来提供group之间的CPU比例控制(让不同的cgroup按照对应 * 的比例来分享CPU),也可以通过cpu.cfs_quota_us来进行配额设定(与RT的 * 带宽控制类似)。CFS group_sched带宽控制是容器实现的基础底层技术之一 * * root_task_group 是默认的根task_group,其他的cpu cgroup都会以它做为 * parent或者ancestor。这里的初始化将root_task_group与rq的cfs运行队列 * 关联起来,这里做的很有意思,直接将root_task_group->cfs_rq[cpu] = &rq->cfs * 这样在cpu cgroup根下的进程或者cgroup tg的sched_entity会直接加入到rq->cfs * 队列里,可以减少一层查找开销。 */root_task_group.shares = ROOT_TASK_GROUP_LOAD;INIT_LIST_HEAD(&rq->leaf_cfs_rq_list);rq->tmp_alone_branch = &rq->leaf_cfs_rq_list;init_cfs_bandwidth(&root_task_group.cfs_bandwidth);init_tg_cfs_entry(&root_task_group, &rq->cfs, NULL, i, NULL);#endif /* CONFIG_FAIR_GROUP_SCHED */ rq->rt.rt_runtime = def_rt_bandwidth.rt_runtime;#ifdef CONFIG_RT_GROUP_SCHED/* 初始化rq上的rt运行队列,与上面的CFS的组调度初始化类似 */init_tg_rt_entry(&root_task_group, &rq->rt, NULL, i, NULL);#endif #ifdef CONFIG_SMP/* * 这里将rq与默认的def_root_domain进行关联,如果是SMP系统,那么后面 * 在sched_init_smp的时候,内核会创建新的root_domain,然后替换这里 * def_root_domain */rq_attach_root(rq, &def_root_domain);#endif /* CONFIG_SMP */ } /* * 注册CFS的SCHED_SOFTIRQ软中断服务函数 * 这个软中断住要是周期性负载均衡以及nohz idle load balance而准备的 */ init_sched_fair_class(); scheduler_running = 1;}四、多核调度初始化(sched_init_smp)
start_kernel
|----rest_init
|----kernel_init
|----kernel_init_freeable
|----smp_init
|----sched_init_smp
|---- sched_init_numa
|---- sched_init_domains
|---- build_sched_domains
多核调度初始化主要是完成调度域/调度组的初始化(当然根域也会做,但相对而言,根域的初始化会比较简单)。
Linux 是一个可以跑在多种芯片架构,多种内存架构(UMA/NUMA)上运行的操作系统,所以 Linu x需要能够适配多种物理结构,所以它的调度域设计与实现也是相对比较复杂的。
4.1、调度域实现原理在讲具体的调度域初始化代码之前,我们需要先了解调度域与物理拓扑结构之间的关系(因为调度域的设计是与物理拓扑结构息息相关的,如果不理解物理拓扑结构,那么就没有办法真正理解调度域的实现)
CPU的物理拓扑图
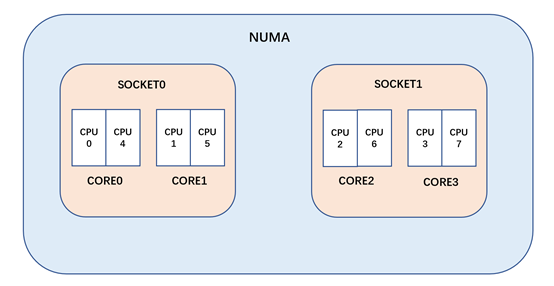
我们假设一个计算机系统(与 intel 芯片类似,但缩小 CPU 核心数,以方便表示):
双 socket 的计算机系统,每个 socket 都是2核4线程组成,那么这个计算机系统就应该是一个4核8线程的 NUMA 系统(上面只是 intel 的物理拓扑结构,而像 AMD ZEN 架构采用了 chiplet 的设计,它在 MC 与 NUMA 域之间会多一层 DIE 域)。
第一层(SMT 域):
如上图的 CORE0,2个超线程构成了 SMT 域。对于 intel cpu 而言,超线程共享了 L1 与 L2(甚至连 store buffe 都在一定程度上共享),所以 SMT 域之间互相迁移是没有任何缓存热度损失的
第二层(MC 域):
如上图 CORE0 与 CORE1,他们位于同一个 SOCKET,属于 MC 域。对于 intel cpu 而言,他们一般共享 LLC(一般是 L3),在这个域里进程迁移虽然会失去 L1 与 L2 的热度,但 L3 的缓存热度还是可以保持的
第三层(NUMA域):
如上图的 SOCKET0 和 SOCKET1,它们之间的进程迁移会导致所有缓存热度的损失,会有较大的开销,所以 NUMA 域的迁移需要相对的谨慎。
正是由于这样的硬件物理特性(不同层级的缓存热度、NUMA 访问延迟等硬件因素),所以内核抽象了 sched_domain 和 sched_group 来表示这样的物理特性。在做负载均衡的时候,根据相应的调度域特性,做不同的调度策略(例如负载均衡的频率、不平衡的因子以及唤醒选核逻辑等),从而在CPU 负载与缓存亲和性上做更好的平衡。
调度域具体实现
接下来我们可以看看内核如何在上面的物理拓扑结构上建立调度域与调度组的
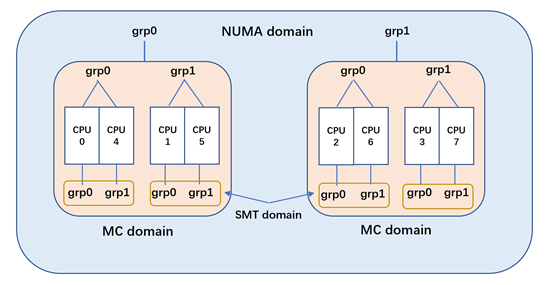
内核会根据物理拓扑结构建立对应层次的调度域,然后在每层调度域上再建立相应的调度组。调度域在做负载均衡,是在对应层次的调度域里找到负载最重的 busiest sg(sched_group),然后再判断 buiest sg 与 local sg(但前 CPU 所在的调度组)的负载是否不均。如果存在负载不均的情况,则会从 buiest sg 里选择 buisest cpu,然后进行2个 CPU 间的负载平衡。
SMT 域是最底层的调度域,可以看到每个超线程对就是一个 smt domain。smt domain 里有2个 sched_group,而每个 sched_group 则只会有一个CPU。所以 smt 域的负载均衡就是执行超线程间的进程迁移,这个负载均衡的时间最短,条件最宽松。
而对于不存在超线程的架构(或者说芯片没有开启超线程),那么最底层域就是MC域(这个时候就只有2层域,MC 与 NUMA)。这样 MC 域里每个 CORE 都是一个 sched_group,内核在调度的时候也可以很好的适应这样的场景。
MC 域则是 socket 上 CPU 所有的 CPU 组成,而其中每个 sg 则为上级 smt domain 的所有CPU构成。所以对于上图而言,MC 的 sg 则由2个 CPU 组成。内核在 MC 域这样设计,可以让 CFS 调度类在唤醒负载均衡以及空闲负载均衡时,要求 MC 域的 sg 间需要均衡。
这个设计对于超线程来说很重要,我们在一些实际的业务里也可以观察到这样的情况。例如,我们有一项编解码的业务,发现它在某些虚拟机里的测试数据较好,而在某些虚拟机里的测试数据较差。通过分析后发现,这是由于是否往虚拟机透传超线程信息导致的。当我们向虚拟机透传超线程信息后,虚拟机会形成2层调度域(SMT 与 MC域),而在唤醒负载均衡的时候,CFS 会倾向于将业务调度到空闲的 sg 上(即空闲的物理 CORE,而不是空闲的 CPU),这个时候业务在 CPU 利用率不高(没有超过40%)的时候,可以更加充分的利用物理CORE的性能(还是老问题,一个物理CORE上的超线程对,它们同时运行 CPU 消耗型业务时,所获得的性能增益只相当于单线程1.2倍左右。),从而获得较好的性能增益。而如果没有透传超线程信息,那么虚拟机只有一层物理拓扑结构(MC域),那么由于业务很可能被调度通过一个物理 CORE 的超线程对上,这样会导致系统无法充分利用物理CORE 的性能,从而导致业务性能偏低。
NUMA 域则是由系统里的所有 CPU 构成,SOCKET 上的所有 CPU 构成一个 sg,上图的 NUMA 域由2个 sg 构成。NUMA 的 sg 之间需要有较大的不平衡时(并且这里的不平衡是 sg 级别的,即要 sg 上所有CPU负载总和与另外一个 sg 不平衡),才能进行跨 NUMA 的进程迁移(因为跨 NUMA 的迁移会导致 L1 L2 L3 的所有缓存热度损失,以及可能引发更多的跨 NUMA 内存访问,所以需要小心应对)。
从上面的介绍可以看到,通过 sched_domain 与 sched_group 的配合,内核能够适配各种物理拓扑结构(是否开启超线程、是否开启使用 NUMA),高效的使用 CPU 资源。
smp_init
/* * Called by boot processor to activate the rest. * * 在SMP架构里,BSP需要将其他的非boot cp全部bring up */void __init smp_init(void){ int num_nodes, num_cpus; unsigned int cpu; /* 为每个CPU创建其idle thread */ idle_threads_init(); /* 向内核注册cpuhp线程 */ cpuhp_threads_init(); pr_info('Bringing up secondary CPUs ...n'); /* * FIXME: This should be done in userspace --RR * * 如果CPU没有online,则用cpu_up将其bring up */ for_each_present_cpu(cpu) {if (num_online_cpus() >= setup_max_cpus) break;if (!cpu_online(cpu)) cpu_up(cpu); } .............}
在真正开始 sched_init_smp 调度域初始化之前,需要先 bring up 所有非 boot cpu,保证这些 CPU 处于 ready 状态,然后才能开始多核调度域的初始化。
sched_init_smp
那这里我们来看看多核调度初始化具体的代码实现(如果没有配置 CONFIG_SMP,那么则不会执行到这里的相关实现)
sched_init_numa
sched_init_numa() 是用来检测系统里是否为 NUMA,如果是的则需要动态添加 NUMA 域。
/* * Topology list, bottom-up. * * Linux默认的物理拓扑结构 * * 这里只有三级物理拓扑结构,NUMA域是在sched_init_numa()自动检测的 * 如果存在NUMA域,则会添加对应的NUMA调度域 * * 注:这里默认的 default_topology 调度域可能会存在一些问题,例如 * 有的平台不存在DIE域(intel平台),那么就可能出现LLC与DIE域重叠的情况 * 所以内核会在调度域建立好后,在cpu_attach_domain()里扫描所有调度 * 如果存在调度重叠的情况,则会destroy_sched_domain对应的重叠调度域 */static struct sched_domain_topology_level default_topology[] = {#ifdef CONFIG_SCHED_SMT { cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },#endif#ifdef CONFIG_SCHED_MC { cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },#endif { cpu_cpu_mask, SD_INIT_NAME(DIE) }, { NULL, },};
Linux默认的物理拓扑结构
/* * NUMA调度域初始化(根据硬件信息创建新的sched_domain_topology物理拓扑结构) * * 内核在默认情况下并不会主动添加NUMA topology,需要根据配置(如果开启了NUMA) * 如果开启了NUMA,这里就要根据硬件拓扑信息来判断是否需要添加 * sched_domain_topology_level 域(只有添加了这个域之后,内核才会在后面初始化 * sched_domain的时候创建NUMA DOMAIN) */void sched_init_numa(void){ ................... /* * 这里会根据distance检查是否存在NUMA域(甚至存在多级NUMA域),然后根据 * 情况将其更新到物理拓扑结构里。后面的建立调度域的时候,就会这个新的 * 物理拓扑结构来建立新的调度域 */ for (j = 1; j < level; i++, j++) {tl[i] = (struct sched_domain_topology_level){ .mask = sd_numa_mask, .sd_flags = cpu_numa_flags, .flags = SDTL_OVERLAP, .numa_level = j, SD_INIT_NAME(NUMA)}; } sched_domain_topology = tl; sched_domains_numa_levels = level; sched_max_numa_distance = sched_domains_numa_distance[level - 1]; init_numa_topology_type();}
检测系统的物理拓扑结构,如果存在 NUMA 域则需要将其加到 sched_domain_topology 里,后面就会根据 sched_domain_topology 这个物理拓扑结构来建立相应的调度域。
sched_init_domains
下面接着分析 sched_init_domains 这个调度域建立函数
/* * Set up scheduler domains and groups. For now this just excludes isolated * CPUs, but could be used to exclude other special cases in the future. */int sched_init_domains(const struct cpumask *cpu_map){ int err; zalloc_cpumask_var(&sched_domains_tmpmask, GFP_KERNEL); zalloc_cpumask_var(&sched_domains_tmpmask2, GFP_KERNEL); zalloc_cpumask_var(&fallback_doms, GFP_KERNEL); arch_update_cpu_topology(); ndoms_cur = 1; doms_cur = alloc_sched_domains(ndoms_cur); if (!doms_cur)doms_cur = &fallback_doms; /* * doms_cur[0] 表示调度域需要覆盖的cpumask * * 如果系统里用isolcpus=对某些CPU进行了隔离,那么这些CPU是不会加入到调度 * 域里面,即这些CPU不会参于到负载均衡(这里的负载均衡包括DL/RT以及CFS)。 * 这里用 cpu_map & housekeeping_cpumask(HK_FLAG_DOMAIN) 的方式将isolate * cpu去除掉,从而在保证建立的调度域里不包含isolate cpu */ cpumask_and(doms_cur[0], cpu_map, housekeeping_cpumask(HK_FLAG_DOMAIN)); /* 调度域建立的实现函数 */ err = build_sched_domains(doms_cur[0], NULL); register_sched_domain_sysctl(); return err;}
/* * Build sched domains for a given set of CPUs and attach the sched domains * to the individual CPUs */static intbuild_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr){ enum s_alloc alloc_state = sa_none; struct sched_domain *sd; struct s_data d; struct rq *rq = NULL; int i, ret = -ENOMEM; struct sched_domain_topology_level *tl_asym; bool has_asym = false; if (WARN_ON(cpumask_empty(cpu_map)))goto error; /* * Linux里的绝大部分进程都为CFS调度类,所以CFS里的sched_domain将会被频繁 * 的访问与修改(例如nohz_idle以及sched_domain里的各种统计),所以sched_domain * 的设计需要优先考虑到效率问题,于是内核采用了percpu的方式来实现sched_domain * CPU间的每级sd都是独立申请的percpu变量,这样可以利用percpu的特性解决它们 * 间的并发竞争问题(1、不需要锁保护 2、没有cachline伪共享) */ alloc_state = __visit_domain_allocation_hell(&d, cpu_map); if (alloc_state != sa_rootdomain)goto error; tl_asym = asym_cpu_capacity_level(cpu_map); /* * Set up domains for CPUs specified by the cpu_map: * * 这里会遍历cpu_map里所有CPU,为这些CPU创建与物理拓扑结构对应( * for_each_sd_topology)的多级调度域。 * * 在调度域建立的时候,会通过tl->mask(cpu)获得cpu在该级调度域对应 * 的span(即cpu与其他对应的cpu组成了这个调度域),在同一个调度域里 * 的CPU对应的sd在刚开始的时候会被初始化成一样的(包括sd->pan、 * sd->imbalance_pct以及sd->flags等参数)。 */ for_each_cpu(i, cpu_map) {struct sched_domain_topology_level *tl; sd = NULL;for_each_sd_topology(tl) { int dflags = 0; if (tl == tl_asym) {dflags |= SD_ASYM_CPUCAPACITY;has_asym = true; } sd = build_sched_domain(tl, cpu_map, attr, sd, dflags, i); if (tl == sched_domain_topology)*per_cpu_ptr(d.sd, i) = sd; if (tl->flags & SDTL_OVERLAP)sd->flags |= SD_OVERLAP; if (cpumask_equal(cpu_map, sched_domain_span(sd)))break;} } /* * Build the groups for the domains * * 创建调度组 * * 我们可以从2个调度域的实现看到sched_group的作用 * 1、NUMA域 2、LLC域 * * numa sched_domain->span会包含NUMA域上所有的CPU,当需要进行均衡的时候 * NUMA域不应该以cpu为单位,而是应该以socket为单位,即只有socket1与socket2 * 极度不平衡的时候才在这两个SOCKET间迁移CPU。如果用sched_domain来实现这个 * 抽象则会导致灵活性不够(后面的MC域可以看到),所以内核会以sched_group来 * 表示一个cpu集合,每个socket属于一个sched_group。当这两个sched_group不平衡 * 的时候才会允许迁移 * * MC域也是类似的,CPU可能是超线程,而超线程的性能与物理核不是对等的。一对 * 超线程大概等于1.2倍于物理核的性能。所以在调度的时候,我们需要考虑超线程 * 对之间的均衡性,即先要满足CPU间均衡,然后才是CPU内的超线程均衡。这个时候 * 用sched_group来做抽象,一个sched_group表示一个物理CPU(2个超线程),这个时候 * LLC保证CPU间的均衡,从而避免一种极端情况:超线程间均衡,但是物理核上不均衡 * 的情况,同时可以保证调度选核的时候,内核会优先实现物理线程,只有物理线程 * 用完之后再考虑使用另外的超线程,让系统可以更充分的利用CPU算力 */ for_each_cpu(i, cpu_map) {for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) { sd->span_weight = cpumask_weight(sched_domain_span(sd)); if (sd->flags & SD_OVERLAP) {if (build_overlap_sched_groups(sd, i)) goto error; } else {if (build_sched_groups(sd, i)) goto error; }} } /* * Calculate CPU capacity for physical packages and nodes * * sched_group_capacity 是用来表示sg可使用的CPU算力 * * sched_group_capacity 是考虑了每个CPU本身的算力不同(最高主频设置不同、 * ARM的大小核等等)、去除掉RT进程所使用的CPU(sg是为CFS准备的,所以需要 * 去掉CPU上DL/RT进程等所使用的CPU算力)等因素之后,留给CFS sg的可用算力(因为 * 在负载均衡的时候,不仅应该考虑到CPU上的负载,还应该考虑这个sg上的CFS * 可用算力。如果这个sg上进程较少,但是sched_group_capacity也较小,也是 * 不应该迁移进程到这个sg上的) */ for (i = nr_cpumask_bits-1; i >= 0; i--) {if (!cpumask_test_cpu(i, cpu_map)) continue; for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) { claim_allocations(i, sd); init_sched_groups_capacity(i, sd);} } /* Attach the domains */ rcu_read_lock(); /* * 将每个CPU的rq与rd(root_domain)进行绑定,并且会检查sd是否有重叠 * 如果是的则需要用destroy_sched_domain()将其去掉(所以我们可以看到 * intel的服务器是只有3层调度域,DIE域其实与LLC域重叠了,所以在这里 * 会被去掉) */ for_each_cpu(i, cpu_map) {rq = cpu_rq(i);sd = *per_cpu_ptr(d.sd, i); /* Use READ_ONCE()/WRITE_ONCE() to avoid load/store tearing: */if (rq->cpu_capacity_orig > READ_ONCE(d.rd->max_cpu_capacity)) WRITE_ONCE(d.rd->max_cpu_capacity, rq->cpu_capacity_orig); cpu_attach_domain(sd, d.rd, i); } rcu_read_unlock(); if (has_asym)static_branch_inc_cpuslocked(&sched_asym_cpucapacity); if (rq && sched_debug_enabled) {pr_info('root domain span: %*pbl (max cpu_capacity = %lu)n', cpumask_pr_args(cpu_map), rq->rd->max_cpu_capacity); } ret = 0;error: __free_domain_allocs(&d, alloc_state, cpu_map); return ret;}
到目前为止,我们已经将内核的调度域构建起来了,CFS 可以利用 sched_domain 来完成多核间的负载均衡了。
五、结语本文主要介绍了内核调度器的基本概念,并通过分析5.4内核中调度器的初始化代码,介绍了调度域、调度组等基本概念的具体落地方式。整体上,5.4内核相比3.x内核,在调度器初始化逻辑,以及调度器相关的基本设计(概念/关键结构)上没有本质的变化,也从侧面印证了内核调度器设计的“稳定”和“优雅”。
以上就是分析Linux内核调度器源码之初始化的详细内容,更多关于Linux内核调度器源码 初始化的资料请关注好吧啦网其它相关文章!
相关文章:
 网公网安备
网公网安备