文章列表
-
- python 开心网和豆瓣日记爬取的小爬虫
- 目录项目地址:开心网日记爬取使用代码豆瓣日记爬取使用代码Roadmap项目地址:https://github.com/aturret/python-crawler-exercise用到了BeautifulSoup4,请先安装。pip install beautifulsoup4开心网日记爬取kaix...
- 日期:2022-06-14
- 浏览:103

-
- 媒体化的豆瓣如何?媒体化的豆瓣能成功吗
- 现在的豆瓣要借助于先天优势成为内容产业的弄潮儿。不过要把内容平台走通,挑战也很大,豆瓣能成功吗?
- 日期:2023-04-02
- 浏览:415
-
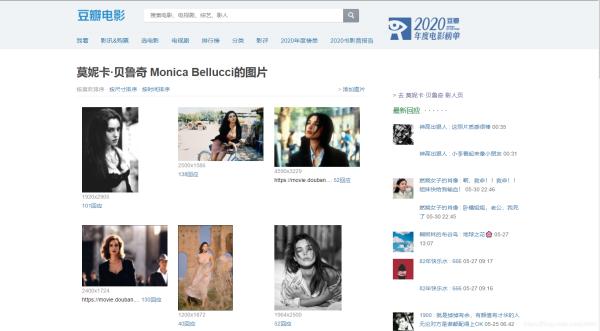
- Python爬虫实战之使用Scrapy爬取豆瓣图片
- 使用Scrapy爬取豆瓣某影星的所有个人图片以莫妮卡·贝鲁奇为例1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目创建的项目结构如下2.为了方便使用pycharm执行scrapy项目,新建main.pyfrom scra...
- 日期:2022-06-14
- 浏览:71
-
- 教你如何利用第三方平台:豆瓣、论坛、博客营销等进行引流【干货】
- 本文主要为大家介绍几种如何利用第三方豆瓣、论坛、博客营销等平台进行引流的方法,有兴趣的朋友们就来了解下吧
- 日期:2023-04-02
- 浏览:14
-
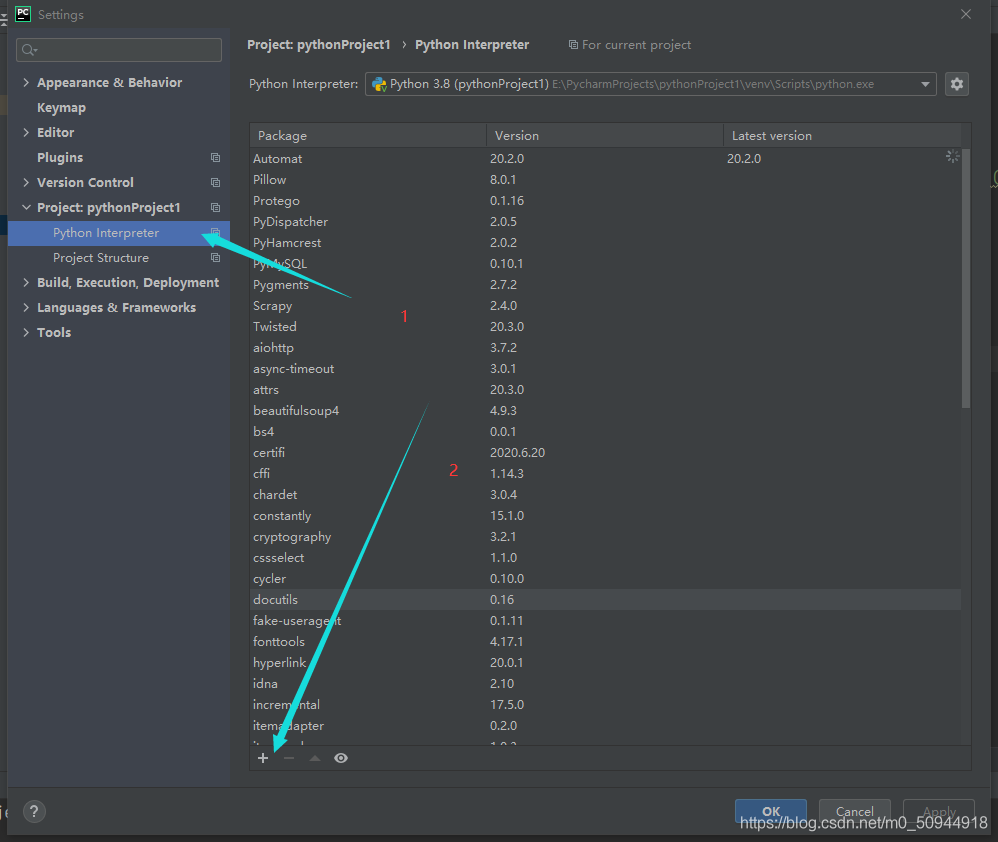
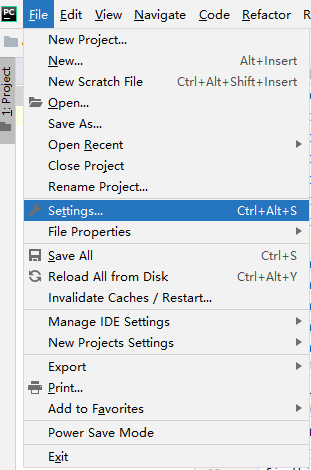
- pycharm配置python 设置pip安装源为豆瓣源
- 豆瓣镜像源:https://pypi.douban.com/simple/file >> setting最后点击OK即可PyCharm基本使用1、在PyCharm下为python项目配置python本地解释器setting-->Project:pycharm workspace--...
- 日期:2022-06-28
- 浏览:12

-
- 豆瓣十年的兴衰史:一个典型精英社区的起伏介绍
- 今天小编为大家带来豆瓣十年的兴衰史,看看曾经一个典型精英社区是如何到现在这个情景。文章有点长,有兴趣的朋友可以过来参考一下哦
- 日期:2023-04-02
- 浏览:678
-
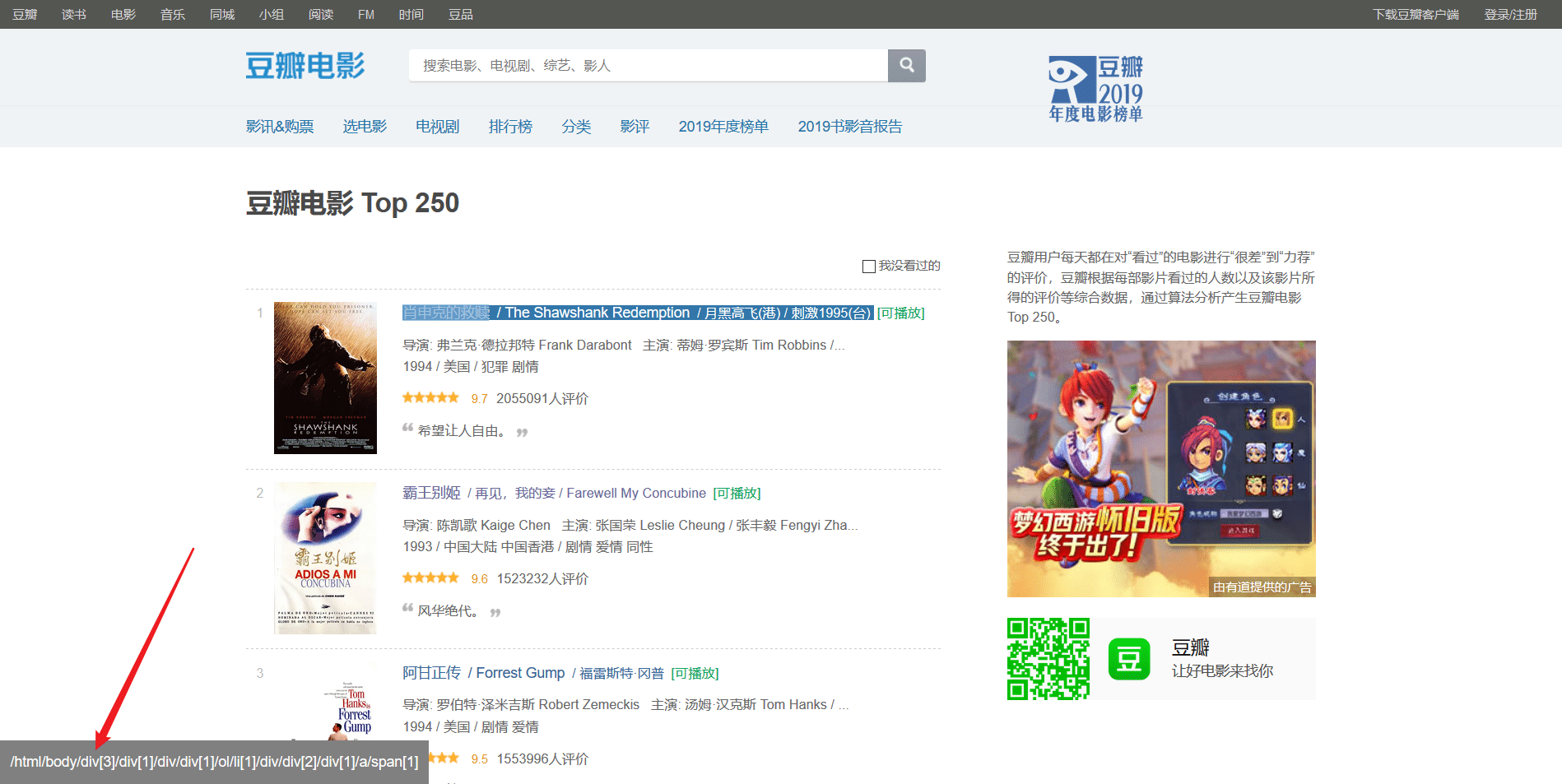
- Python爬虫获取豆瓣电影并写入excel
- 豆瓣电影排行榜前250 分为10页,第一页的url为https://movie.douban.com/top250,但实际上应该是https://movie.douban.com/top250?start=0 后面的参数0表示从第几个开始,如0表示从第一(肖申克的救赎)到第二十五(触不可及)...
- 日期:2022-07-15
- 浏览:12
-
- python使用re模块爬取豆瓣Top250电影
- 爬?四步原理:1.发送请求:requests2.获取相应数据:对方及其直接返回3.解析并提取想要的数据:re4.保存提取后的数据:with open()文件处理爬?三步曲:1.发送请求2.解析数据3.保存数据注意:豆瓣网页爬虫必须使用请求头,否则服务器不予返回数据import reimport re...
- 日期:2022-07-07
- 浏览:1
-
- Python爬取豆瓣数据实现过程解析
- 代码如下from bs4 import BeautifulSoup #网页解析,获取数据import sys #正则表达式,进行文字匹配import reimport urllib.request,urllib.error #指定url,获取网页数据import xlwt #使用表格import s...
- 日期:2022-07-07
- 浏览:1
-
- python爬取豆瓣电影排行榜(requests)的示例代码
- ’’’ 爬取豆瓣电影排行榜 设计思路: 1、先获取电影类型的名字以及特有的编号 2、将编号向ajax发送get请求获取想要的数据 3、将数据存放进excel表格中’’’环境部署:软件安装:Python 3.7.6官网地址:https://www.python.org/安装地址:https://www...
- 日期:2022-06-27
- 浏览:2
 网公网安备
网公网安备