文章列表
-
- Django结合使用Scrapy爬取数据入库的方法示例
- 在django项目根目录位置创建scrapy项目,django_12是django项目,ABCkg是scrapy爬虫项目,app1是django的子应用2.在Scrapy的settings.py中加入以下代码import osimport syssys.path.append(os.path.dir...
- 日期:2024-09-11
- 浏览:37
- 标签: Django

-
- Python Scrapy多页数据爬取实现过程解析
- 1.先指定通用模板url = ’https://www.qiushibaike.com/text/page/%d/’#通用的url模板pageNum = 12.对parse方法递归处理parse第一次调用表示的是用来解析第一页对应页面中的数据对后面的页码的数据要进行手动发送if self.pageN...
- 日期:2022-07-21
- 浏览:125
-
- python爬虫scrapy框架之增量式爬虫的示例代码
- scrapy框架之增量式爬虫一 、增量式爬虫什么时候使用增量式爬虫:增量式爬虫:需求 当我们浏览一些网站会发现,某些网站定时的会在原有的基础上更新一些新的数据。如一些电影网站会实时更新最近热门的电影。那么,当我们在爬虫的过程中遇到这些情况时,我们是不是应该定期的更新程序以爬取到更新的新数据?那么,增...
- 日期:2022-06-27
- 浏览:8
-
- Python爬虫实战之使用Scrapy爬取豆瓣图片
- 使用Scrapy爬取豆瓣某影星的所有个人图片以莫妮卡·贝鲁奇为例1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目创建的项目结构如下2.为了方便使用pycharm执行scrapy项目,新建main.pyfrom scra...
- 日期:2022-06-14
- 浏览:78

-
- Django-Scrapy生成后端json接口的方法示例
- 网上的关于django-scrapy的介绍比较少,该博客只在本人查资料的过程中学习的,如果不对之处,希望指出改正;以后的博客可能不会再出关于django相关的点;人心太浮躁,个人深度不够,只学习了一些皮毛,后面博客只求精,不求多;希望能坚持下来。加油!学习点: 实现效果 django与scrap...
- 日期:2024-05-27
- 浏览:84
- 标签: JavaScript
-
- python中scrapy处理项目数据的实例分析
- 在我们处理完数据后,习惯把它放在原有的位置,但是这样也会出现一定的隐患。如果因为新数据的加入或者其他种种原因,当我们再次想要启用这个文件的时候,小伙伴们就会开始着急却怎么也翻不出来,似乎也没有其他更好的搜集办法,而重新进行数据整理显然是不现实的。下面我们就一起看看python爬虫中scrapy处理项...
- 日期:2022-07-04
- 浏览:69
-
- 如何在django中运行scrapy框架
- 1.新建一个django项目,2.前端展示一个按钮<form action='/start/' method='POST'> {% csrf_token %} <input type='submit' value='启动爬虫'></form>3.在dj...
- 日期:2024-10-09
- 浏览:3
- 标签: Django
-
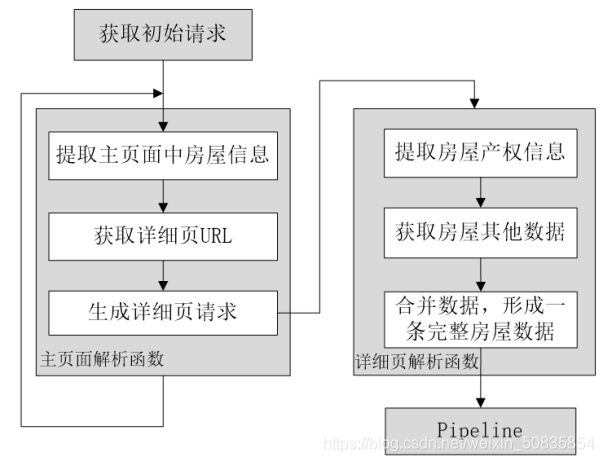
- Python scrapy爬取苏州二手房交易数据
- 一、项目需求使用Scrapy爬取链家网中苏州市二手房交易数据并保存于CSV文件中要求:房屋面积、总价和单价只需要具体的数字,不需要单位名称。删除字段不全的房屋数据,如有的房屋朝向会显示“暂无数据”,应该剔除。保存到CSV文件中的数据,字段要按照如下顺序排列:房屋名称,房屋户型,建筑面积,房屋朝向,装...
- 日期:2022-06-16
- 浏览:25
-
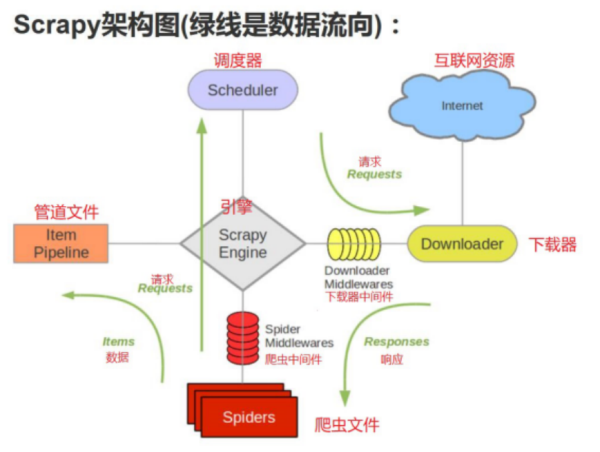
- Python爬虫基础之简单说一下scrapy的框架结构
- scrapy 框架结构思考 scrapy 为什么是框架而不是库? scrapy是如何工作的?项目结构在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:注意:创建项目时,会在当前目录下新建爬虫项目的目录。这些文件分别是: sc...
- 日期:2022-06-15
- 浏览:85

-
- Python Scrapy图片爬取原理及代码实例
- 1.在爬虫文件中只需要解析提取出图片地址,然后将地址提交给管道在管道文件对图片进行下载和持久化存储class ImgSpider(scrapy.Spider): name = ’img’ # allowed_domains = [’www.xxx.com’] start_urls = [’ht...
- 日期:2022-07-21
- 浏览:75
 网公网安备
网公网安备